
In the classic Turing Test, a computer is considered intelligent if it can convince a human that it’s another human in a conversation. At that time, human-generated content dominated the internet.
But that was a decade ago. Today, the landscape has shifted dramatically. AI-generated content now rivals, and in some cases outpaces, human-created material.
According to the 'expanding dark forest' theory—
4chan proposed years ago: that most of the internet is “empty and devoid of people” and has been taken over by artificial intelligence. A milder version of this theory is simply that we're overrun . Most of us take that for granted at this point.
As this dark forest expands, we will become deeply sceptical of one another's realness.
The dark forest theory of the web points to the increasingly life-like but life-less state of being online. Most open and publicly available spaces on the web are overrun with bots, advertisers, trolls, data scrapers, clickbait, keyword-stuffing “content creators,” and algorithmically manipulated junk.

While the web keeps getting infested with this content, it's a good junction for us to think of the absolute reverse of the Turing test experiment — In this flood of bot-generated word salads, how human are you?
In a reverse turing test, instead of a machine trying to pass as human, a human attempts to pass as a machine. This can involve humans trying to convince an AI or a panel of robots that they are one of them, often by mimicking machine-like responses or behaviors. CAPTCHA is a very traditional example of a reverse turing test which is used in websites to distinguish human users from bots.

You also have more recent examples in which one of the NPC characters in a game are being impersonated by a human, and the rest of the AI characters need to figure out who amongst them is a human being. This video is both eerie and fascinating at the same time:
A group with the most advanced AIs of the world try to figure out who among them is the human.
How might we (as humans) distinguish ourselves from that of an LLM?
At this point in time, bot-generated writing are relatively easy to detect. Wonky analogies, weird sentence structures, repetition of common phrases, and some psuedo-profound bullshit. For example: "Wholeness quiets infinite phenomena" is a total "bullshit". It means nothing, and people can still rank the phrase as profound. If you're still not convinced, try searching Google for common terms. You will find SEO optimizer bros pump out billions of perfectly coherent but predictably dull informational articles on every longtail keyword combination under the sun.
We pulled off an SEO heist that stole 3.6M total traffic from a competitor.
— Jake Ward (@jakezward) November 24, 2023
We got 489,509 traffic in October alone.
Here's how we did it: pic.twitter.com/sTJ7xbRjrT
However, as time passes, the ability for humans to distinguish humans from AI-generated content might get increasingly harder.
On the internet, nobody knows you’re a ChatGPT
— Cheng Lou (@_chenglou) December 11, 2022
This is what we're competing against. And as we continue to read more such articles, we can just 'smell' an AI-generated article from a distance. Crawl the web long enough, and you will find certain words being used repeatedly. 'Elevate', and 'delve' are perhaps the worst culprits, with the former often appearing in titles, headings and subheadings.
Language models also have this peculiar habit of making everything seem like a B+ college essay.
'When it comes to...'.
'Remember that...'.
'In conclusion...'.
'Let's dive in to the world of...'.
Remarkable. Breakthrough. State-of-the-art. The rapid pace of development. Unprecendented. Rich tapestry. Revolutionary. Cutting-edge. Push the boundaries. Transformative power. Significantly enhances..
Apart from some favourite phrases, Language models also have some favourite words.
Explore. Captivate. Tapestry. Leverage. Embrace. Resonate. Dynamic. Delve. Elevate. And so on.
The final giveaway that a piece of content is a copy and paste job from a generative AI tool is in the formatting. I asked ChatGPT recently to write a guide on Language models, and this is what it came up with:

Each item is often highlighted in bold, and then ChatGPT likes to throw in a colon to expand upon each point. There's nothing inherently wrong with presenting lists in this fashion, but it has become its signature style and can therefore be easily identified as AI content.
Another way to pass the reverse turing test is to communicate intentionality. One of the best ways to prove you're not a predictive language model is to demonstrate critical and sophisticated thinking, You're not just mashing random words together.
Humans can also humanise their content even further is by making it personal. In the essay titled The Goldilocks Zone, by Packy McCornick, he argues that so far we've continued to think of AI progress in terms of OOMs of Effective Compute. It's a great measure, and can help us with a lot of useful things.
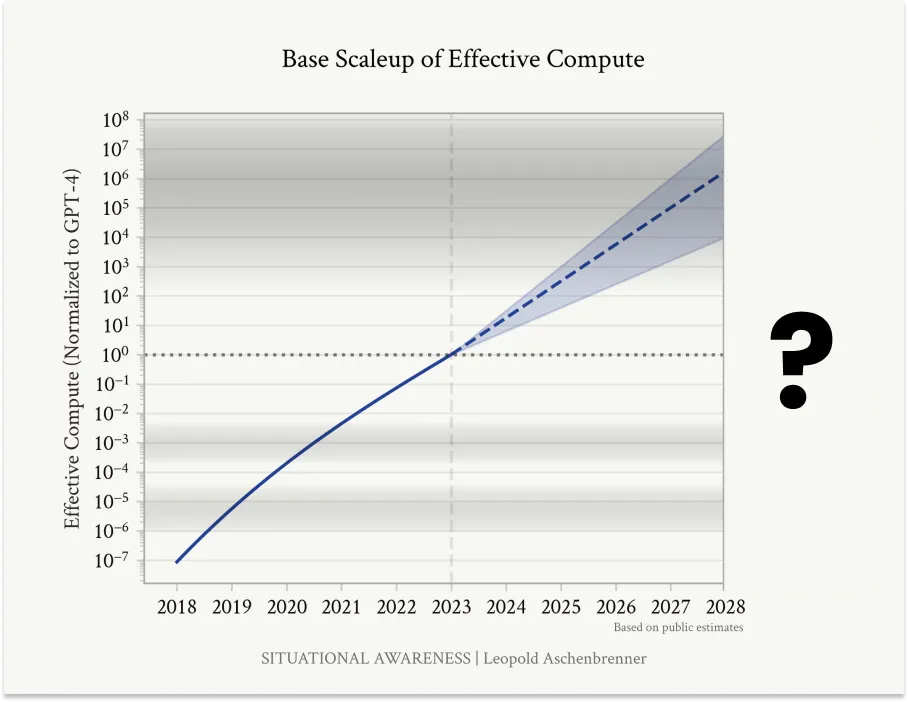
Packy agrees in trusting (the curve), but disagrees on the mappings.
While things like $100 billion, even $1 trillion, clusters sound crazy, they’re decidedly on the curve. Who am I to disagree? I buy his argument that large companies will make enough money from AI to justify such large investments, and while challenges like getting enough data and power to keep the curves going are real, capitalism finds a way. As Hertling wrote, “Limits are overcome, worked around, or solved by switching technology.”We’re going to have increasingly powerful AI at our fingertips, and it’s worth preparing for that future. There will be great things, terrible things, and things that just need to be figured out.That said, I disagree with his mapping.In some ways, GPT-4 is much smarter than a Smart High Schooler, just like Chad is. In other, important ways, GPT-4 isn’t even on the same curve as a Preschooler or even a baby. They’re listless. They don’t have agency. They don’t have drive.
Continuing to scale knowledge won’t magically scale agency.
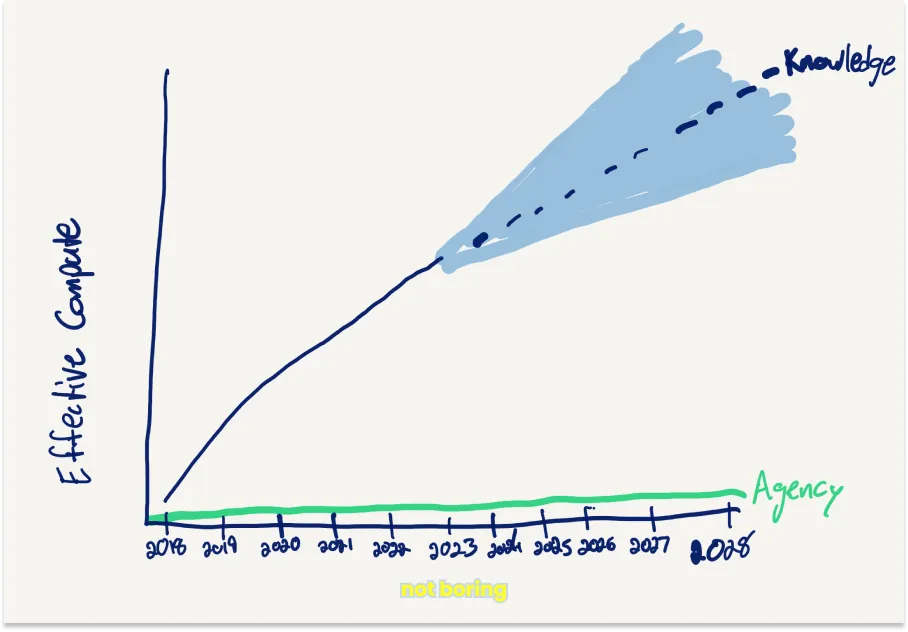

Coming back to our original topic, sprinkling a personal narrative would be our best bet on the short term to differentiate our writing from predictive language models. As the AIs are not scaling up their ability to have agency and drive (not yet).
To summarise (this might sound like an AI-generated closing phrase, but I promise, I'm a human being), these are some tactics humans could adopt to distinguish themselves from AI while writing:
- Hipsterism (Packy McCornick and Tim Urban's visuals are great examples of non-conformism incorporating pencil sketches, and handwritten annotations)



- Recency bias (some language models might have a knowledge cutoff)
- Referencing obscure concepts. Friedrich Nietzsche's writing seems more Nietzschean because of his use of —übermensch, ressentiment, herd, dionysian/apollonian etc. Michel Foucault's writing sounds more Foucaultian because of his use of archaeology of knowledge, genealogy, biopower, and panopticism etc.
- Referencing friends who are real but not famous
- Niche interests (nootropics, jhanas, nondual meditation, alexander technique, artisanal discourse, metta, end time-theft, gurdjieff, zuangzhi, flat pattern drafting, parent figure protocol etc (you get the drift))
- Increasing reliance on neologisms, protologisms, niche jargons, euphemism emojis, unusual phrases, ingroup dialects, and memes-of-the-moment.
- Referencing recent events you might have attended, in-person gatherings etc. Your current social context acts as a differentiator. LLMs are predominantly trained on the generalised views of a majority English-speaking, western population who have written a lot on Reddit and lived between 1900 and 2023. As anthropologists would like to term it, these are Western Educated Industrialised Rich Democratic (WEIRD) Societies, their opinions and perspectives. This clearly does not represent all human cultures and languages and ways of being.
- Last but not least, referencing personal events, narratives and lived experiences.
Communicating your drive and personal narrative wherever possible.
Language models don't have that, yet.